
Tecnologia
Cosa si intende per data lake?
03
Mag
Mag
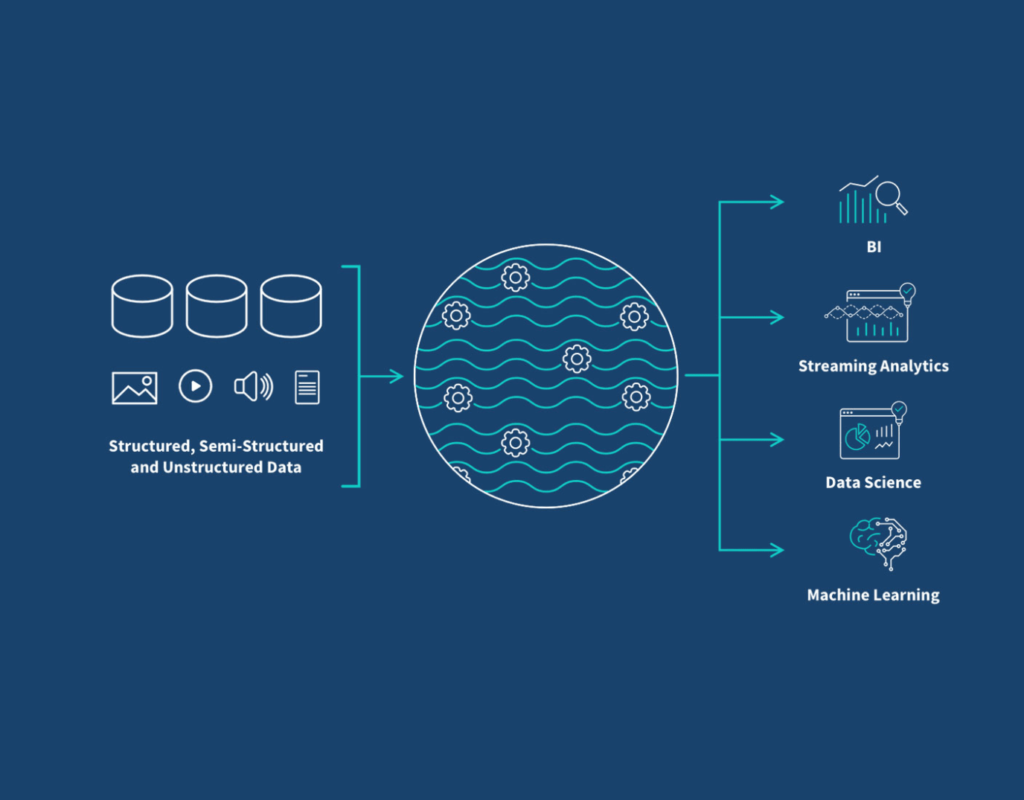
Un data lake è un repository centralizzato progettato per archiviare grandi volumi di dati strutturati, semi-strutturati e non strutturati nel loro formato nativo.
Pensa ad un lago: proprio come un lago naturale accoglie una varietà di acque, un data lake può contenere diversi tipi di dati da diverse fonti, senza bisogno di una strutturazione o di una formattazione preliminare.
Ecco alcuni dei principali vantaggi di un data lake:
Archiviazione scalabile: I data lake possono scalare orizzontalmente per archiviare enormi quantità di dati, con la possibilità di aggiungerne sempre di più man mano che le esigenze crescono.
Flessibilità dei dati: I data lake possono archiviare qualsiasi tipo di dato, indipendentemente dal suo formato o dalla sua struttura. Questo li rende ideali per l’archiviazione di big data complessi, come immagini, video, sensori IoT e dati social media.
Analisi avanzata: I data lake facilitano l’analisi di grandi volumi di dati da diverse fonti, utilizzando strumenti di analisi avanzati e tecniche di machine learning. Questo può aiutare le organizzazioni a ottenere informazioni preziose dai propri dati e prendere decisioni migliori.
Conformità e sicurezza: I data lake possono essere implementati con funzionalità di sicurezza e conformità robuste per proteggere i dati sensibili e soddisfare i requisiti normativi.